Job Interview in Microsoft
Summary
Last month I had an opportunity to interview at Microsoft for a developer position with experience in backend, specifically a role to help out developing their in-house observability for Azure SQL systems. The interview was comprised of 3 different interviews the same evening and I myself experienced what the standard big tech company interview everyone talks about.
Here is the main layout of how this company interviews:
Interview #1 - Algorithm problem
You are given a file containing a memory dump. Inside it there are n blocks where each block is determined by a base index, i.e. the beginning of the region, and an offset that indicates how many bytes from the base address delimit the region. Your task is to create an algorithm that quickly determines if a given memory region determined by the base + offset is contained within a region in the memory file dump. Ideally O(log(n). I wasn’t asked to code this directly, it was more of a way to explain myself the idea which I would approach solving this.
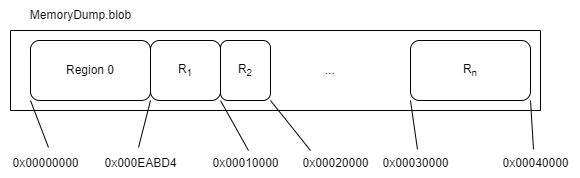
Solution
- Create a binary tree, this one should be ideally balanced (read more in wikipedia), where the value of the node is the base index or the index + off set.
- Once the tree is created search for the node that contains the index value of the input or the one that the next ascending value is greater.
- If none is found it means that the memory isn’t even contained in within the ranges of memory addresses.
Interview #2 - Code solving problem
Given a matrix of strings representing blocks from a city, each entry determines if it contains a McDonald’s = m and KFC = k. 1 or more adjacent entries are considered to be in the same region if they have a restaurant of the same franchise. Given an input matrix M, determine how many regions composed by McDonald’s are in the matrix. This can be resolved by designing an algorithm that uses depth first search to traverse the matrix and identify the ‘m’ values:
- First traverse the matrix, it doesn’t really matter in which direction or order as long as you iterate over each value contained.
- When the desired value, in this case an ‘m’ is found add 1 to the number of regions.
- Then inspect all of the surrounding regions, i.e. up-down-left-right. *Note we have to be careful of not stepping out of bounds which can cause a runtime error.
- If it’s an ‘m’ repeat from step 2
- If it’s not an ‘m’ or has already been visited, stop - No need to proceed.
As you can see the step c. can also be evaluated at the same time as the first statement in step 2. The previously described algorithm is an example of Depth First Search, if you look carefully how the nodes are traversed you will see that once we hit an m, we proceed to inspect the adjacent nodes. I was asked to write the code using one of the Leetcode site sandbox, here’s what I came up with in typescript:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
function numMcDonaldsRegions(matrix: string[][]): number {
if (matrix.length === 0 || matrix[0].length === 0) return 0;
const rows = matrix.length;
const cols = matrix[0].length;
const visited: boolean[][] = Array.from({ length: rows }, () => Array(cols).fill(false));
let count = 0;
function dfs(row: number, col: number): void {
if (row < 0 || row >= rows || col < 0 || col >= cols || visited[row][col]) return;
visited[row][col] = true;
if (matrix[row][col] === 'm') {
// Visit adjacent cells
dfs(row + 1, col);
dfs(row - 1, col);
dfs(row, col + 1);
dfs(row, col - 1);
}
}
for (let i = 0; i < rows; i++) {
for (let j = 0; j < cols; j++) {
if (!visited[i][j] && matrix[i][j] === 'm') {
count++;
dfs(i, j);
}
}
}
return count;
}
// Example usage:
const matrix: string[][] = [
['m', 'k', 'm', 'k'],
['m', 'k', 'k', 'm'],
['k', 'm', 'm', 'k'],
['m', 'k', 'm', 'm']
];
console.log(numMcDonaldsRegions(matrix)); // Output: 5
Interview #3 - System design analysis
Given a system that has a database that contains some metadata of all of the databases in the cloud, there are N clients that are overloading the database with queries. To solve this problem a key/value cache store was implemented as it is faster to read from it than to query directly the database. The end goal is for the clients to get the metadata information stored in the database, this data is stored as a record that composed by a key which is a unique identifier and the value is the metadata as a string (assume it is a JSON).
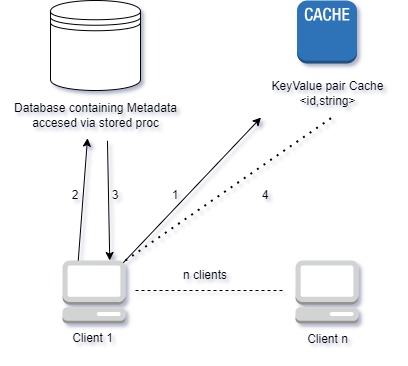
The information flow goes as follows:
- The client requests the value to the cache, if the cache has the value it is returned and goal is achieved.
- If the value is not stored in cache, then the client can proceed to query the database.
- The client gets the value and then…
- Proceeds to update the value in cache so it can be used for future queries by other clients
Design questions and discussions
What would happen if the connection to the database is lost, or if a client fails to update the value in the cache?
Possible solution
- When the client attempts to read from the cache first, if the value for a given id isn’t found, then put a placeholder value that is composed by the id of the client and the timestamp, for example:
<id,"[timestamp]-[clientId]">. After setting a placeholder the client can proceed to read the value from the database. Once the value is obtained it should update the value in the cache store.- If another client requests the same value and finds a key set, but a
[timestamp]-[clientIdentifier]is found as a value, then the client can poll against the cache until the timestamp expires. - If the timestamp expires, then the client can assume that something went wrong when another client was retrieving and updating the value stored in cache, therefore this client can proceed with updating the value in cache with a new “timestamp+clientId”.
- If another client requests the same value and finds a key set, but a
How would you handle the scenario where several clients are reading different values from the database and causing an overload?
Possible solution
An easy fix could be horizontally scaling this database by sharding using a hash method to determine where the value for a given id is stored. We could store the values across several sharded servers and whenever a request for a record comes through we proceed to calculate the value based on a hash: serverIndex = hash(key) % N, where N is the number of servers. Once we have the value of the serverIndex we redirect the request to the appropriate shard and prevent stressing the key/value store by distributing the requests. Note: using a hash function via the modular function is not always the best choice as it may lead to the same problem of overloading a sharded database. Also it may lead to problems when a new database is required to be added as the data grows. There are several ways to manage this such as consistent hashing, which again is not immune to certain scenarios.
Afterthoughts
Although I wasn’t hired, it was a good experience as it reminded me that I need to brush up on my coding skills for what could be thought as simple college exercises for some people. I think I failed awfully on interview #1 and #3.
Lessons learned
- Don’t be afraid to ask if you can use Chat GPT to generate quickly mocked data. Of course, not to solve the problem as this would nullify the point of the interview.
- If you’re doing leetcode type interviews, practice coding exercises focused on data structures as those are harder and will make you think, the ones that are about an input like an array or string usually are a little bit easier as they usually can be solved using brute force algorithms.
- Read more about scalability problems and system design. There are a bunch of good books such as one I’ve been reading recently: System Design Interview, by Alex Xu.
- As always, preparation is required to succeed especially in these kind of tests. Failing when I know it could have done better by preparing sucks.